Extreme Parallel Processing (XPP) For Hive

XPP stands for eXtreme Parallel Processing. For larger systems with more complicated code, XPP helps achieve parallelism on the cluster at the lowest possible level i.e. individual queries to achieve maximum possible utilization.
The motivation for developing XPP
While migrating one of our cross market data modeling systems to the cloud, we tried various approaches to make it run “faster” than the initial 30+ hours. Our approaches included:
- Breaking up the modules (SQL files) into multiple clusters. We decided against this approach because we couldn’t split to more than a few clusters due to the dependencies.
- Running multiple modules on the same cluster. This provided a superior performance compared to running things sequentially, but we still saw that cluster utilization was not optimal.
So, we went one level deeper and parallelized individual queries. We designed something that is generic and can be used by any pattern.
Are there any pre-requisites to use XPP?
As long as you’re able to run your HQL / SQL files sequentially, that’s pretty much it. We recognize the usual “create table”, “alter table”, “drop table”, “insert (into|overwrite) table” and “analyze table” statements.
Also, revisiting the pattern code to ensure queries are appropriately broken up and “parallel-run enabled” will also help.
How does XPP work?
XPP is a 2 step process:
- Build a dependency tree between the queries of the pattern, and split individual SQL statements.
- Parallelize the query executions based on dependencies.
How does it really work?
The dependency tree is built, and first step is complete.
- Split pattern SQL file(s) into individual queries and build a dependency tree.
Determine dependency tree (Using the debug option to just display the results on screen) $ ./depSQL.pl help usage: cat *SQL | ./depSQL.pl genSQL pdistfile=run.txt - ./depSQL.pl genSQL pdistfile=run.txt file1.SQL file2.SQL file3.SQL ... options: genSQL if specified, generates a .SQL file for each query. pdistfile if specified, creates a file suitable to pipe into pdist.pl. - dash specifies to read stdin. debug dump output to stdout. prefix output files have prefix: default is empty.Let’s take a sample dummy pattern.pattern.SQL $ cat pattern.SQL drop table a; create table a as select * from blah ; drop table b; create table b as select * from glah; ; drop table c; create table c as select * from a inner join b on a.id=b.id ; drop table c2; -- this is a comment about query a b c create table c2 as select * from a left outer join b on a.id=b.id ; drop table a; drop table b;Now, let's run the pattern code throughdepSQL.pl. Notice the comments inserted by depSQL:Determine dependency tree (Using the debug option to just display the results on screen) $ ./depSQL.pl debug pattern.SQL -- query 0, depends on: drop table a ; -- query 1, depends on: 0 create table a as select * from blah ; -- query 2, depends on: drop table b ; -- query 3, depends on: 2 create table b as select * from glah ; -- query 5, depends on: drop table c ; -- query 6, depends on: 5, 1, 3 create table c as select * from a inner join b on a.id=b.id ; -- query 7, depends on: drop table c2 ; -- query 8, depends on: 1, 3, 7 -- this is a comment about query a b c create table c2 as select * from a left outer join b on a.id=b.id ; -- query 9, depends on: 1, 6, 8 drop table a ; -- query 10, depends on: 3, 6, 8 drop table b ;The output looks good; Now, let's finalize the dependency tree and split the code into multiple SQL files.
Using the output above, here’s where you actually run the pattern queries in parallel.
depSQL.pl in action $ ./depSQL.pl genSQL pdistfile=pattern_dep.txt pattern.SQL $ ls -l total 32 -rw-r--r-- 1 srikars finlab 40 Nov 17 16:35 0.SQL -rw-r--r-- 1 srikars finlab 70 Nov 17 16:35 1.SQL -rw-r--r-- 1 srikars finlab 48 Nov 17 16:35 10.SQL -rw-r--r-- 1 srikars finlab 40 Nov 17 16:35 2.SQL -rw-r--r-- 1 srikars finlab 70 Nov 17 16:35 3.SQL -rw-r--r-- 1 srikars finlab 40 Nov 17 16:35 5.SQL -rw-r--r-- 1 srikars finlab 111 Nov 17 16:35 6.SQL -rw-r--r-- 1 srikars finlab 41 Nov 17 16:35 7.SQL -rw-r--r-- 1 srikars finlab 157 Nov 17 16:35 8.SQL -rw-r--r-- 1 srikars finlab 47 Nov 17 16:35 9.SQL -rwxr-xr-x 1 srikars finlab 3178 Nov 17 16:26 depSQL.pl -rw-r--r-- 1 srikars finlab 204 Nov 17 16:35 pattern_dep.txt -rw-r--r-- 1 srikars finlab 379 Nov 17 16:26 pattern.SQL $ head pattern_dep.txt 0.SQL{id=0}{dep=} 1.SQL{id=1}{dep=0} 2.SQL{id=2}{dep=} 3.SQL{id=3}{dep=2} 5.SQL{id=5}{dep=} 6.SQL{id=6}{dep=5,1,3} 7.SQL{id=7}{dep=} 8.SQL{id=8}{dep=1,3,7} 9.SQL{id=9}{dep=1,6,8} 10.SQL{id=10}{dep=3,6,8} - Using the output above, here’s where you actually run the pattern queries in parallel.
pdist.pl in action $ cat pattern_dep.txt | ./pdist.pl threads=5 cmd="./hive_runner_wrapper.sh {}"pdist is the tool used to execute a job in parallel. Parallelism is achieved by passing different parameters to the different threads of the program that's being run. Let’s examine the basic parameters:
cmd= < shell command > This can be any valid shell command. The {}syntax is used to pass whatever comes out of pattern_dep.txt into the shell command as a parameter threads= < number > The number of concurrent threads to run. pdist ensures that it runs the max threads as long as dependencies are met
These two components (depSQL.pl and pdist.pl) form the heart of XPP. Both these files can be downloaded from bottom of this page.
If I set Apache TEZ at the beginning of my file, will the TEZ setting take effect on every query?
Yes! We keep track of "set" and "add file" statements. We can insert those settings appropriately in the individual queries. Let's take an example:
pattern2.SQL
$ cat pattern2.SQL
set hive.execution.engine=tez;
drop table a;
create table a as
select * from blah
;
-- below query runs only on mr
set something=value;
set hive.execution.engine=mr;
drop table b;
create table b as
select * from a full outer join glah
;
-- set back to tez
set hive.execution.engine=tez;
drop table c;
create table c as
select a.*, b.*
from a inner join b on (a.id = b.id)
;
When we pass the file through depSQL, notice that the set statements have been inserted appropriately.
pattern2.SQL through depSQL
$ ./depSQL.pl debug pattern2.SQL
-- query 1, depends on:
set hive.execution.engine=tez;
drop table a
;
-- query 2, depends on: 1
set hive.execution.engine=tez;
create table a as
select * from blah
;
-- query 5, depends on:
set hive.execution.engine=tez;
-- below query runs only on mr
set something=value;
set hive.execution.engine=mr;
drop table b
;
-- query 6, depends on: 2, 5
set hive.execution.engine=tez;
-- below query runs only on mr
set something=value;
set hive.execution.engine=mr;
create table b as
select * from a full outer join glah
;
-- query 8, depends on:
set hive.execution.engine=tez;
-- below query runs only on mr
set something=value;
set hive.execution.engine=mr;
-- set back to tez
set hive.execution.engine=tez;
drop table c
;
-- query 9, depends on: 8, 2, 6
set hive.execution.engine=tez;
-- below query runs only on mr
set something=value;
set hive.execution.engine=mr;
-- set back to tez
set hive.execution.engine=tez;
create table c as
select a.*, b.*
from a inner join b on (a.id = b.id)
;
We keep track of the settings file by individual SQL / HQL file. So, the behavior in XPP is identical to running individual files sequentially in Hive.
What do you do when a query fails?
You have a few options when using pdist.pl.
- “waitonfail”
When a child thread returns failure status (i.e. <> 0) pdist waits for all the currently running threads to complete and then exits with failure status (1). - "dieonfail”
When a child thread returns failure, it quits immediately (i.e. doesn’t wait for other currently running threads to return). If you’re simply running hive jobs, you may never need to use “dieonfail”. Since pdist is not just restricted to running hive, but other things as well, a general option is provided. - Do nothing
When a child process returns failure status, pdist will continue to spawn child processes as much as possible as long as dependencies are met. Only when it hits a dead end (i.e. cannot process further without the failed query being rectified), it ends with error status.
Here’s an example of using the “waitonfail” option.
"waitonfail" Example
$ cat pattern_dep.txt | ./pdist.pl waitonfail threads=5 cmd="./hive_runner_wrapper.sh {}"
In case of failure, does pdist know to “resume” from the point of failure?
Yes, we keep track of what ran and what happened to that run (i.e. did it succeed or fail in a log file). When you use the “recover” parameter while kicking off pdist, we look into this log file to determine where to resume. So, expanding on the same example:
"recover" example
$ cat pattern_dep.txt | ./pdist.pl waitonfail recover log=pattern_track.log threads=5 cmd="./hive_runner_wrapper.sh {}"
Are there cost benefits to using XPP?
Yes, running things faster also means cost savings. The savings would depend on the amount of parallelization that can be achieved and the capacity allotted and utilization.
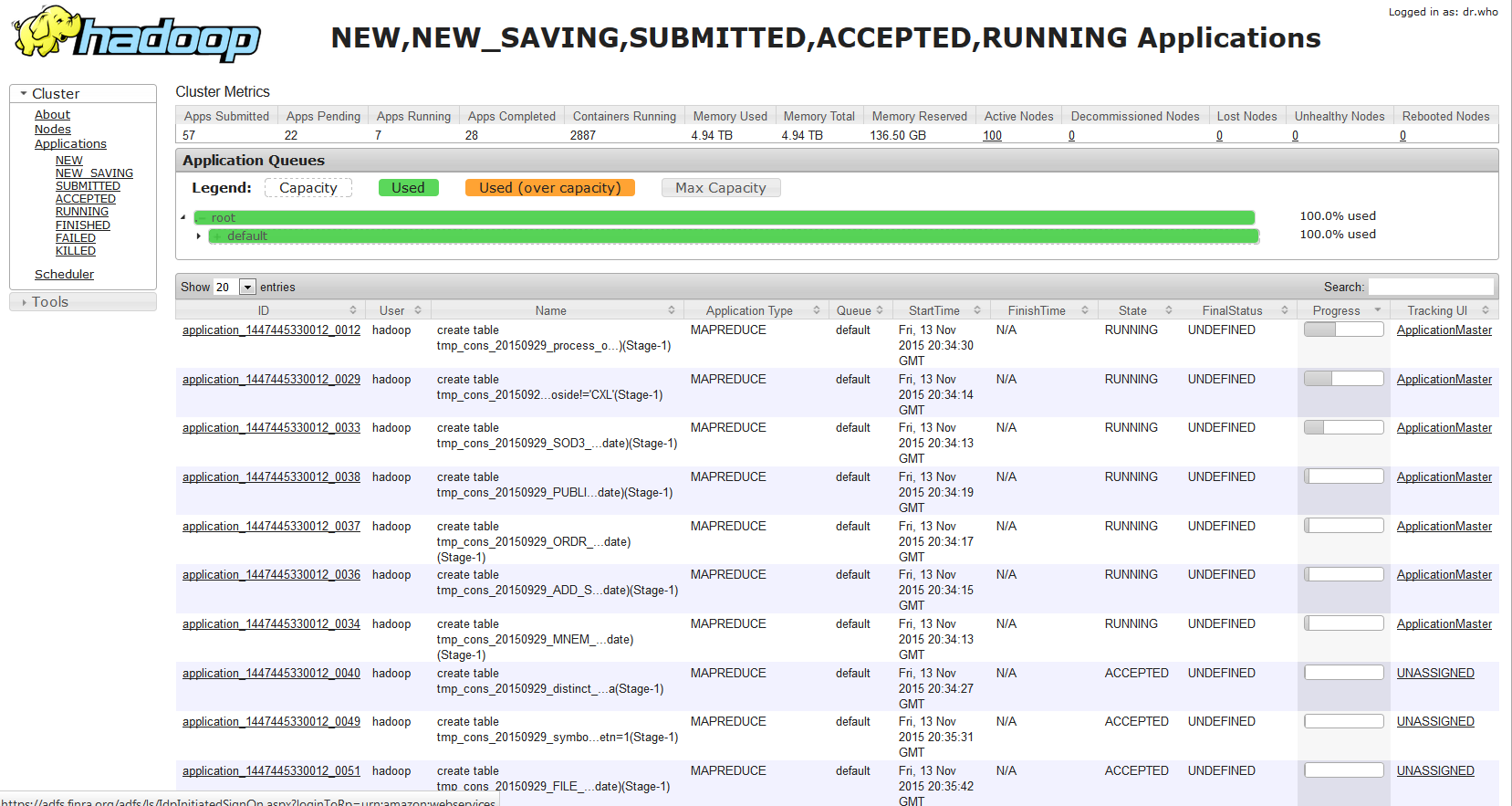
Are there any monitoring tools?
The Hadoop resource manager (// < masterIP>:9026 in AMI 3.9, // < masterIP>:8088 in EMR 4.1) is a great monitoring tool as the cluster is chugging away with multiple queries. Clicking on the Scheduler link shows you something like this where you can watch all the queries coming through pdist and their % complete status.
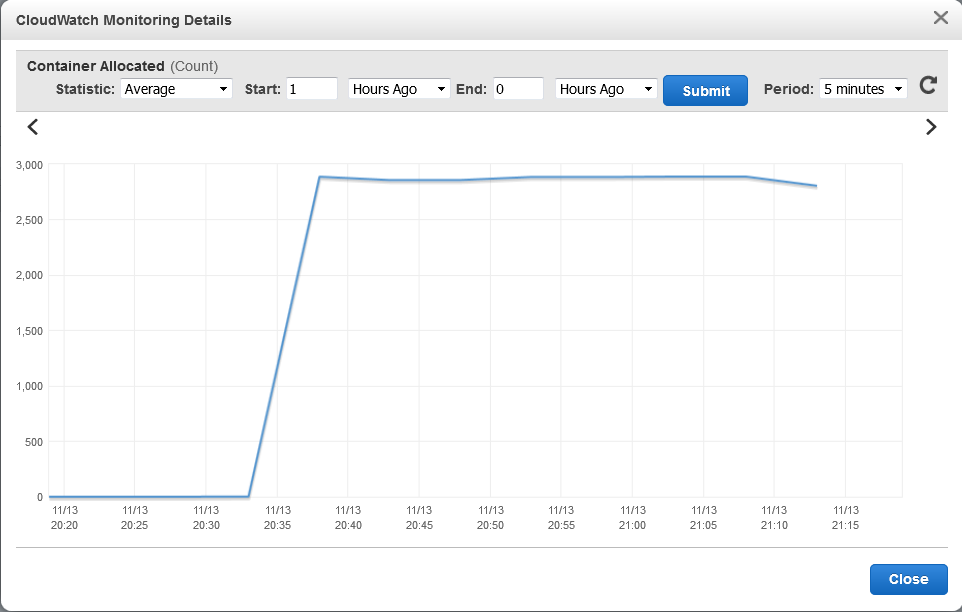
CloudWatch is also pretty good to monitor resource allocation.
For example, containers allocated first and memory available:
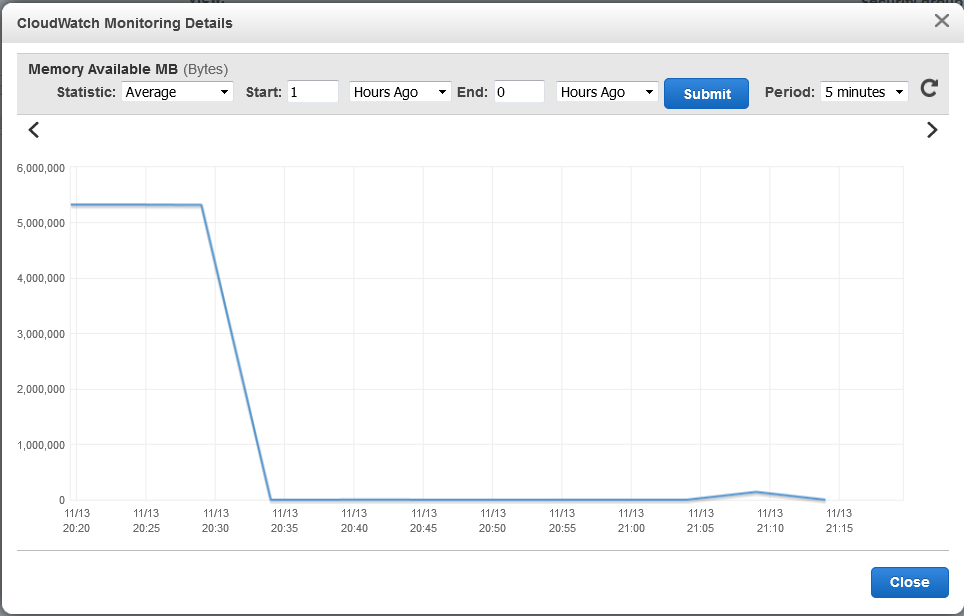
Where can I get the XPP code?
Right here!