Quality Assurance In The Machine Learning Age

How FINRA Assesses Performance of its Machine Learning Models
Data science has come a long way in the past 10 years. As machine learning projects become productionized, they look increasingly like software projects. Focus has shifted from presenting charts to integrating AI software into a production pipeline. There is still plenty of work in the former scenario, but the latter has become more mainstream in the last few years.
Machine learning projects look a lot like software projects, except for one key difference: instead of hard coding business rules, these rules are learned from real world data. This approach is not expected to give perfect results 100% of the time. Rather, the objective is to learn rules that are data-driven and usually provide an approximation or probability of classification or prediction.
As an example, how might we describe the process of recognizing a dress that a customer might want? Is the process similar or different from detecting manipulation in the markets? You might know it when you see it but attempting to hard code solutions to these sorts of tasks with the level of rigor required seems onerous. There are usually enough edge cases that make this approach very challenging. Furthermore, your snapshot of training data can become irrelevant in a changing environment; when the data you use to make decisions changes substantially, your “hard-coded” rules may no longer apply. This is especially true with stock trading strategies; the strategy you developed before the 2008 financial crisis likely won’t work well today because the landscape looks dramatically different.
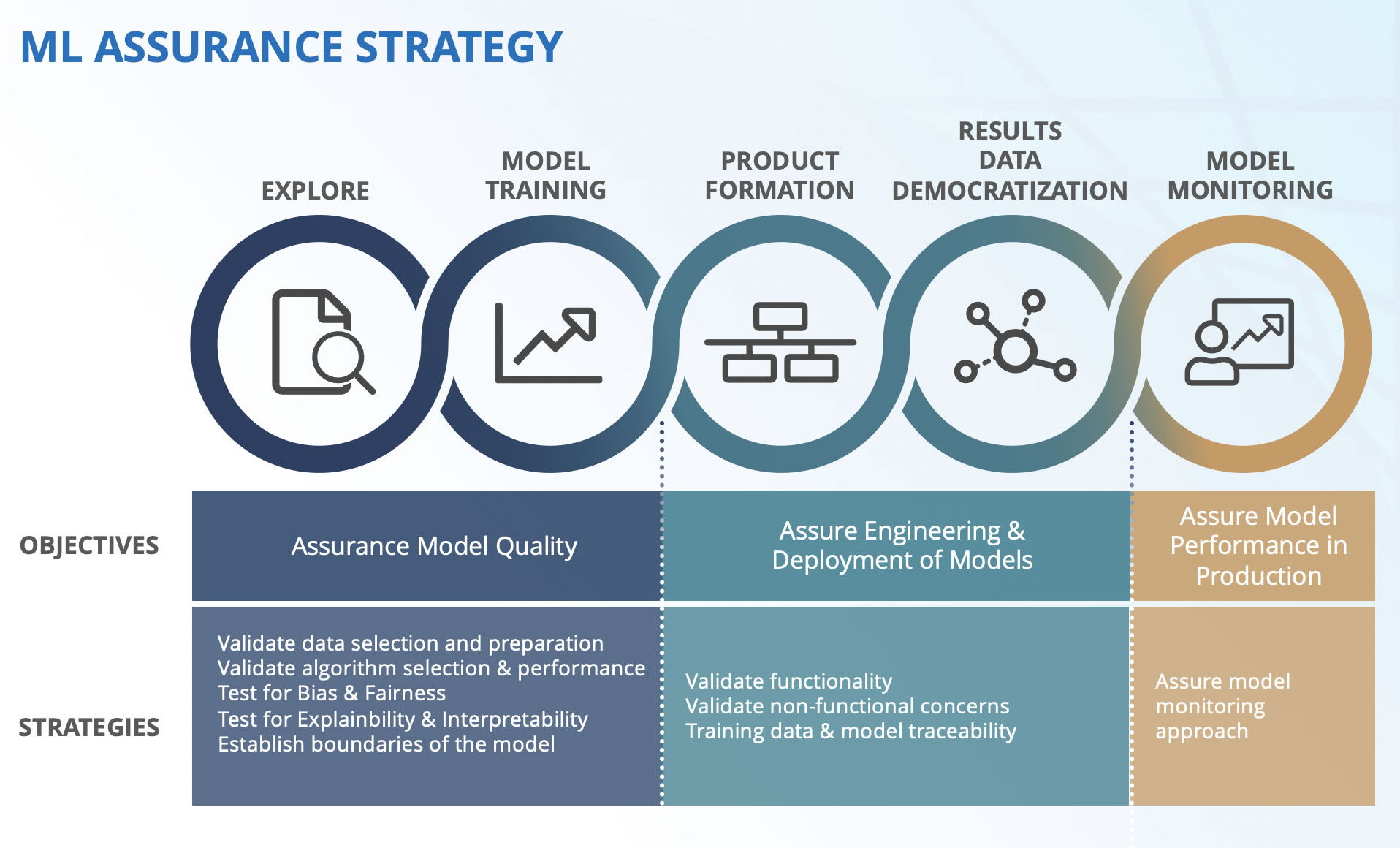
As hardware has improved and memory and computing resources have become much more available, it has become possible to write software that intelligently conducts what we might call probably approximately correct (PAC) learning scenarios. As the name implies, they are not supposed to function perfectly in every example. While solutions of this nature are incredibly useful, measuring performance can be more subtle. This is where a good assurance engineering strategy can bring clarity to project goals, mitigate risks, and help the project better serve the business.
Machine Learning Projects vs Software Projects
There are many testing concerns within a machine learning project, including data selection, feature engineering, algorithm selection, and model drift. Nonfunctional testing like performance and security is also key to meeting compliance requirements.
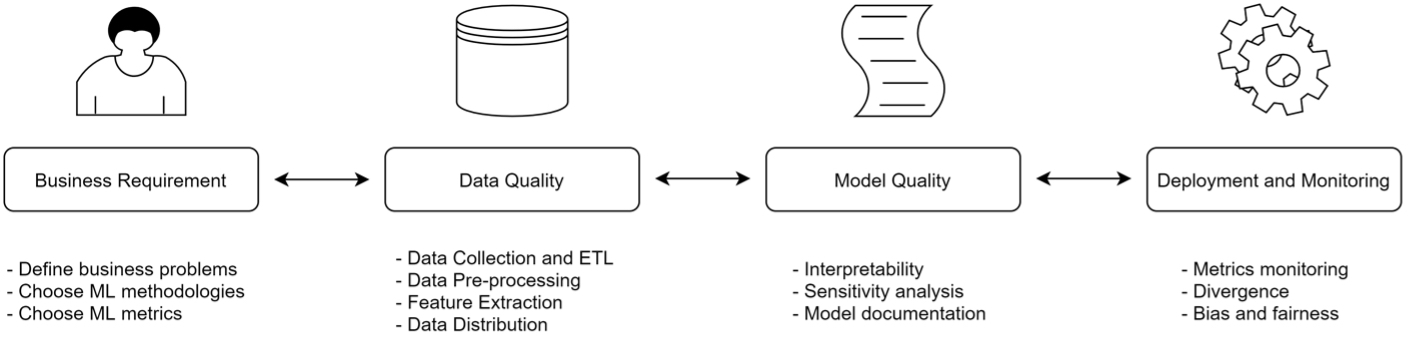
You might be amazed at how many problems in a machine learning pipeline come from ordinary software bugs. The garbage in, garbage out mantra is just as true here as it is anywhere – if the inputs to your pipeline are bad, the outputs are going to be bad, no matter how good your methods or approach are. I once worked with a group that took two full days of debugging to realize that Keras, a Python deep learning library, was not throwing errors when it encountered missing data and the algorithm was silently failing because the pipeline that fed data into it was broken. Data scientists often reach for a notebook when they need a testable software suite. To this end, testing a machine learning project is identical to testing ordinary software. You test all hard-coded aspects of the project the way you would any other pipeline.
Evaluation Metrics
So, if models are not supposed to be perfect, how can we assess performance? There are many metrics, and many of them are specific to the modeling scenario. For example, in binary classification, a model has to label something as true or false. An example at FINRA might be: “Does this look like a case of insider trading?” The model would spit out a number between 0 and 1 with 0 meaning “Definitely not insider trading” and 1 being “Absolutely looks like insider trading.” There are a number of metrics specifically used for binary classification. Other metrics are used for regression (e.g. “What will be the expected price of this stock one minute later?”). All metrics come down to comparing what the model returned to what you would have wanted it to return. For example, in binary classification, we need a list of accounts that were in fact labeled as insider trading and a list of accounts that were not labeled as such, and we would determine that the model did better if it was typically giving higher scores to the insider trading cases than the ones that were not. A metric called ROC AUC is a very robust way of doing this. ROC AUC determines the probability that a randomly chosen case of insider trading would be given a higher score than a randomly chosen instance of non-insider trading. Because FINRA has many use cases where binary classifiers are used to sort accounts from most interesting to least interesting to analysts, we use ROC AUC extensively to assess performance of our models.
The Future of Quality Assurance for Machine Learning
Even as machine learning technology continues to rapidly evolve, there are many machine learning projects with poorly defined business goals. Being able to answer "What do I hope to improve because of this algorithm?" is fundamental to quality assurance, because it is the very definition of quality with respect to the project. At FINRA, we have found that identifying and summarizing examples of poor performing machine learning models to be a critical aspect of our quality assurance strategy. This can include visualizing data in ways that help identify examples with poor performance and assigning uncertainty to a model's predictions when the original model had no such metric. These are some of the problems we are tackling at FINRA, and we strive to continue to improve our ability to engineer quality and performance in our machine learning solutions to help protect investors and ensure the integrity of US financial markets.