Store and Retrieve Spark DataFrames Natively with FINRA’s Herd

What is Herd?
Overview
Herd is big data governance for the cloud. The herd Unified Data Catalog (UDC) helps separate compute from storage in the cloud. Herd job orchestration manages your ETL and analytics processes while tracking all data in the catalog. Here is a quick summary of features:
- Unified Data Catalog - A centralized, auditable catalog for operational usage and data governance
- Lineage Tracking - Capture data ancestry for regulatory, forensic, and analytical purposes
- Cluster Management - Create and launch clusters and load data into clusters from catalog entries
- Job Orchestration - Orchestrate clusters and catalog services to automate processing jobs
Find out more about herd features on our GitHub project page.
Quick Start
The best way to start learning about herd is through the links below. The demo installation process is quick and easy - you can have herd up and running in AWS in 10 to 15 minutes and start registering data immediately afterwards.
What is Herd/Spark DataCatalog API?
DataCatalog library creates DataFrames of data registered with herd. The goal of the library is to provide a facility to create Spark DataFrames with any Business Object Data registered with herd. Using this service catalog, you can browse for available objects, get necessary parameters to query for a specific Business Object Data, get the Business Object Data as a Spark DataFrame, or save a Spark Dataframe to herd.
What Problems are Solved Using DataCatalog?
- Less code writing in your notebook
- Users can load the data without knowing details about the data (e.g., schema, S3 location, etc.), saving the hassle of making extra herd calls to get the schema and location and then having to parse them
- Saves time
- Easy access to data
- Users can save the DataFrame directly in herd without registering the data separately in herd
- Users can share the data registered in herd using saveDataFrame feature.
DataCatalog Features
| API | Description |
|---|---|
| DataCatalog Instance | Constructor for creating a DataCatalog instance. There are 2 ways of creating an instance:
|
| dmWipeNamespace | This function removes objects, schemas, partitions, and files from a namespace |
| getDataAvailability | This function returns all available Business Object Data for range 2000-01-01 to 2099-12-31 from herd into a Spark DataFrame |
| getDataAvailabilityRange | This function returns all available Business Object Data for the given range from herd into a Spark DataFrame |
| getDataFrame | Given the herd object location identifiers, this function will load the data from S3 and return the Spark DataFrame (works for a list of partitions) |
| getPartitions | This function queries and returns the Spark SQL StructFields of partitions of the given object |
| getSchema | This function queries REST and returns the Spark SQL StructFields for the given data object |
| loadDataFrame | This function returns a Spark DataFrame of data registered with herd |
| saveDataFrame | This function saves and registers a DataFrame with herd (supports sub-partitioned data) |
| unionUnionSchema | This function unions the DataFrame (missing columns get null values) |
Steps to Use DataCatalog API
1. Create an uber jar file from the GitHub repo by running mvn clean install command
2.Upload the jar to Jupyter or Databricks notebook or add the following dependency to your local project:
<dependency>
<groupId>org.finra.herd</groupId>
<artifactId>herd-spark-data-catalog</artifactId>
<version>${latest.version}</version>
</dependency>
3. Create your local Spark Session
sparkSession = SparkSession
.builder
.appName ("")
.master ("")
.getOrCreate()
4. Import the library
import org.finra.catalog._
import scala.collection.immutable.Map
5. Test the library for TXT format—see the following example for dataCatalog instance, saveDataFrames, loadDataFrames and getDataFrames feature set:
DataCatalog Instance
- Using CredStash
new DataCatalog(spark, host, credName, AGS, SDLC, credComponent)
Input Parameters-
spark : SparkSession - Spark session defined by user
host : String - host https://host.name.com:port
credName : String - credential name (e.g. username for herd)
credAGS : String - AGS for credential lookup
credSDLC : String - SDLC for credential lookup
credComponent : String - Component for credential lookup - Using Individual Credentials
new DataCatalog(sparkSession, host, USERNAME, PASSWORD)
Input Parameters-
spark : SparkSession - spark session defined by user
host : String - host https://host.name.com:port
username : String - herd username
password : String - herd password
Save, Load and Get DataFrames for TXT Format
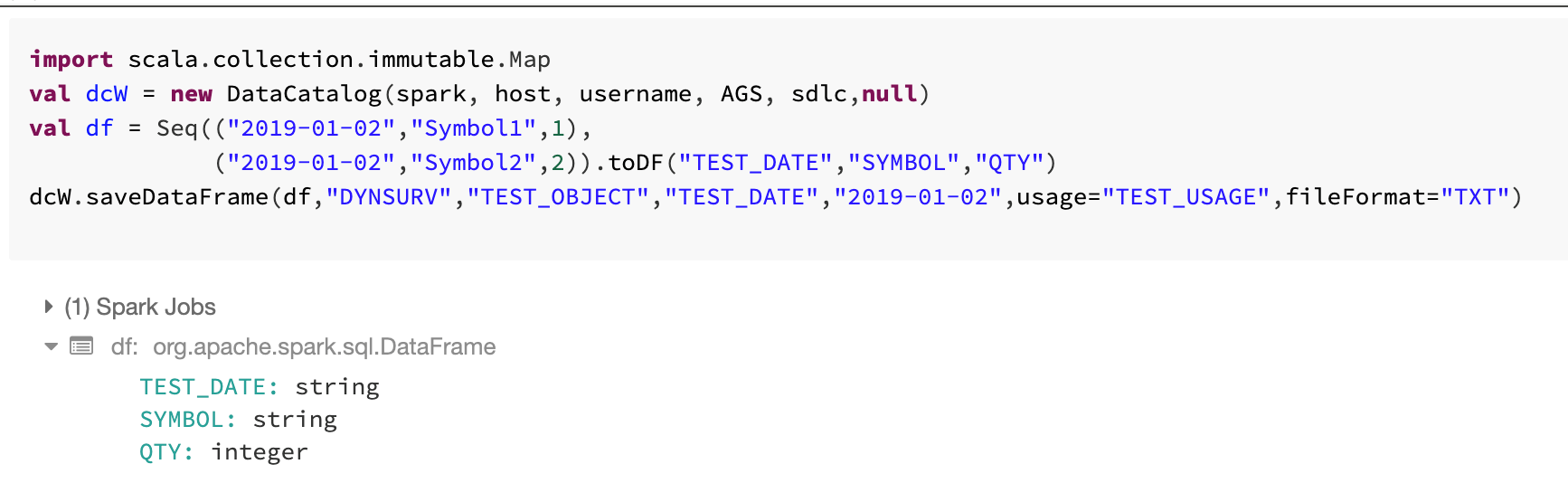
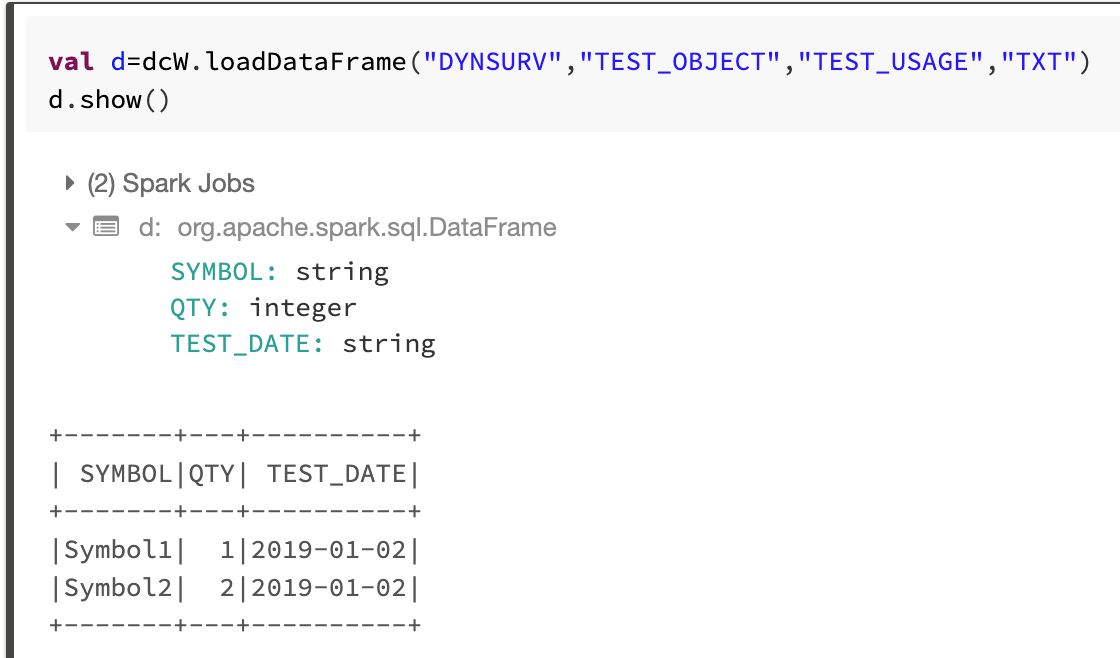
GetDataFrame is different from loadDataFrame because getDataFrame allows you to get data for a range of partition values along with the user-specified data version and format version.

6. Test the library for PARQUET format. See example below for saveDataFrames, loadDataFrames and getDataFrames feature set.
In Parquet, you can also save and load complex datatypes like Map, Array, Struct. Hence data catalog is helpful in dealing with nested and complex data sets too.
Save, Load and Get DataFrames for PARQUET Format with complex dataType

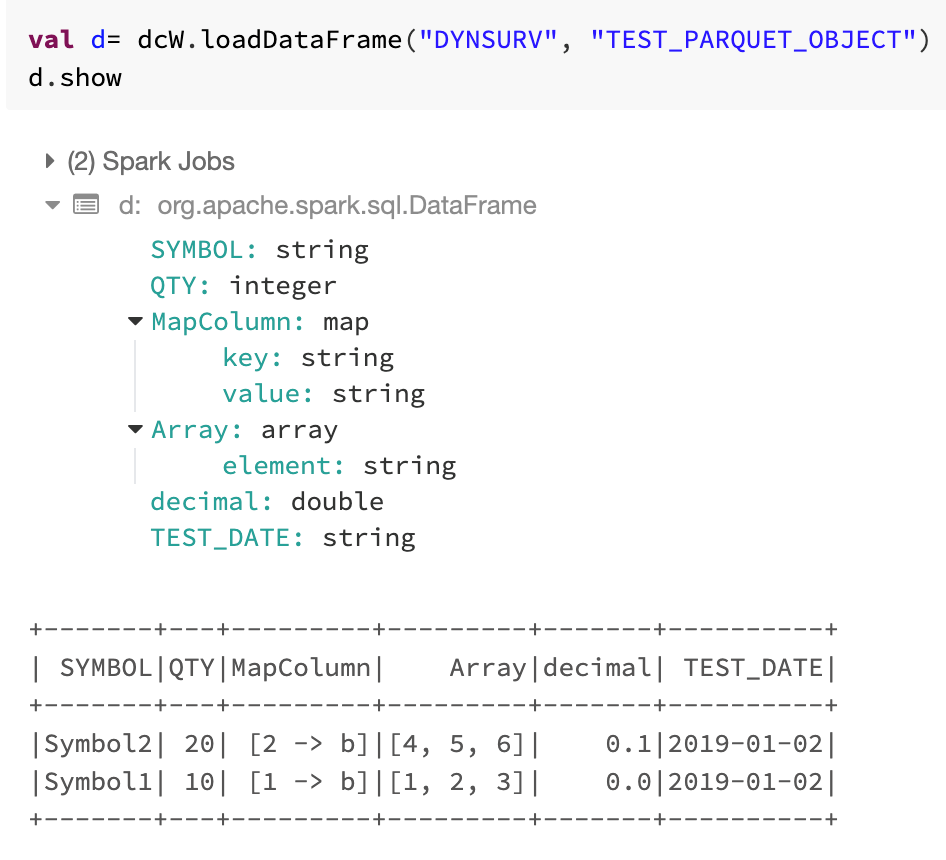
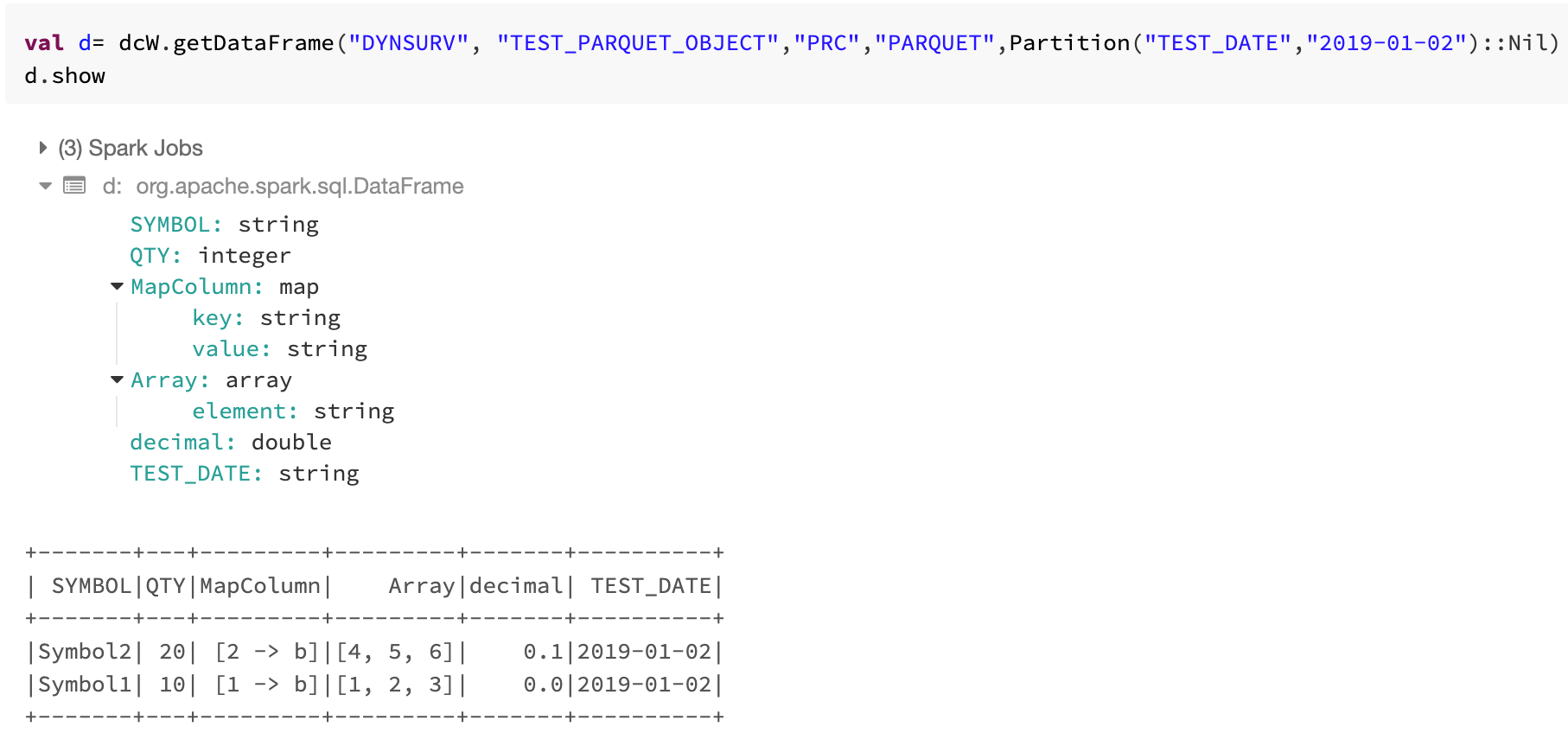
7. Test the library for ORC format. See example below for saveDataFrames, loadDataFrames and getDataFrames feature set.
Save, Load and Get DataFrames for ORC Format with complex datatype
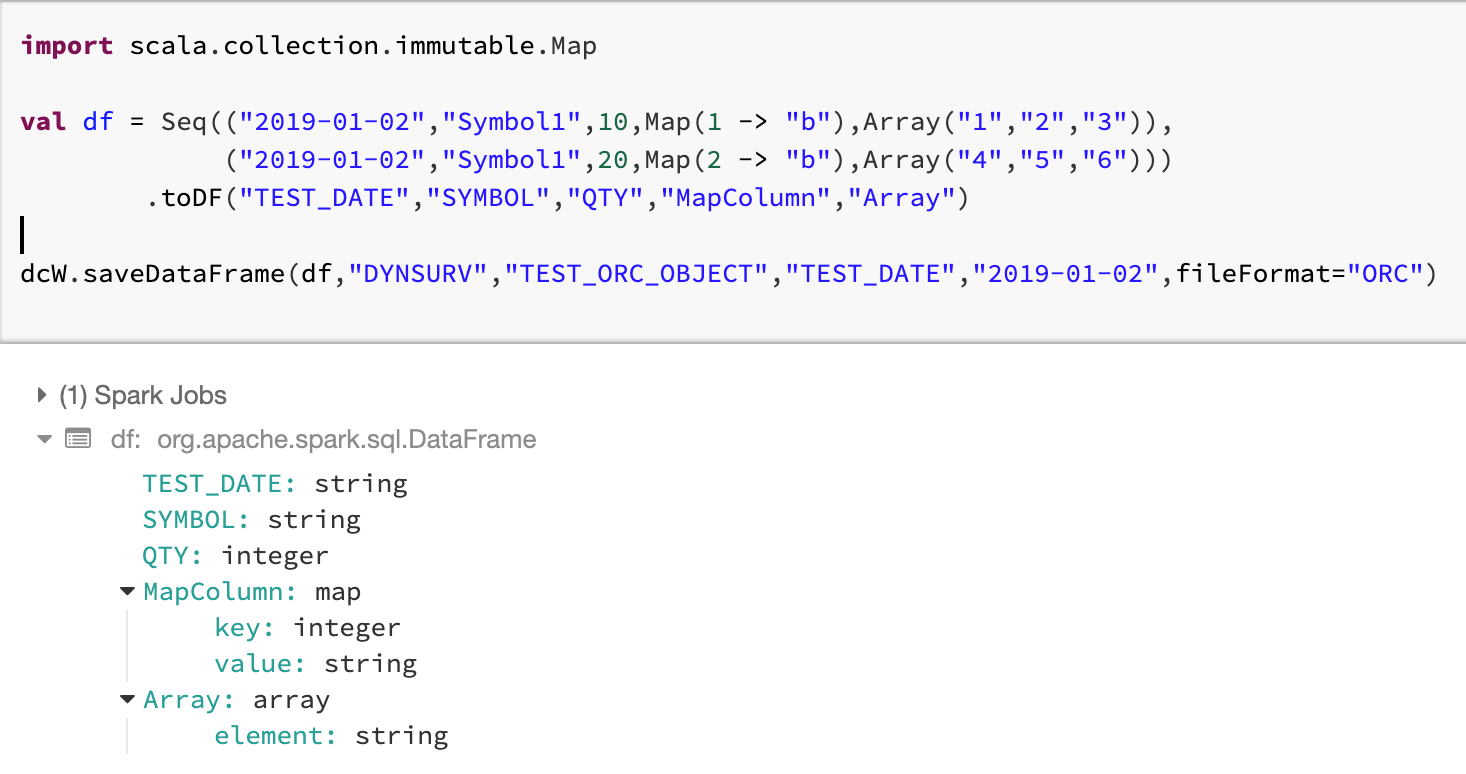
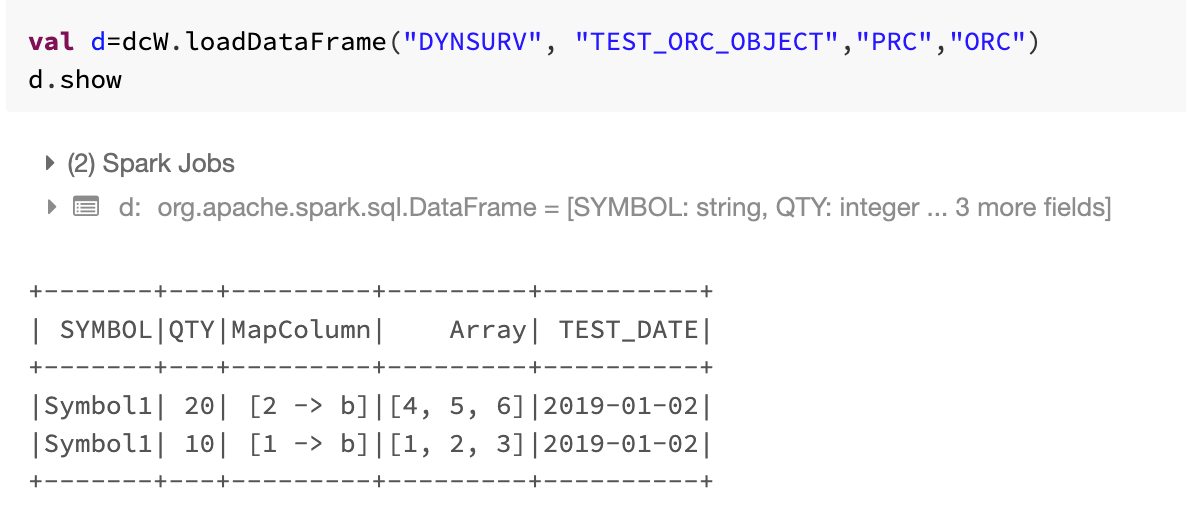
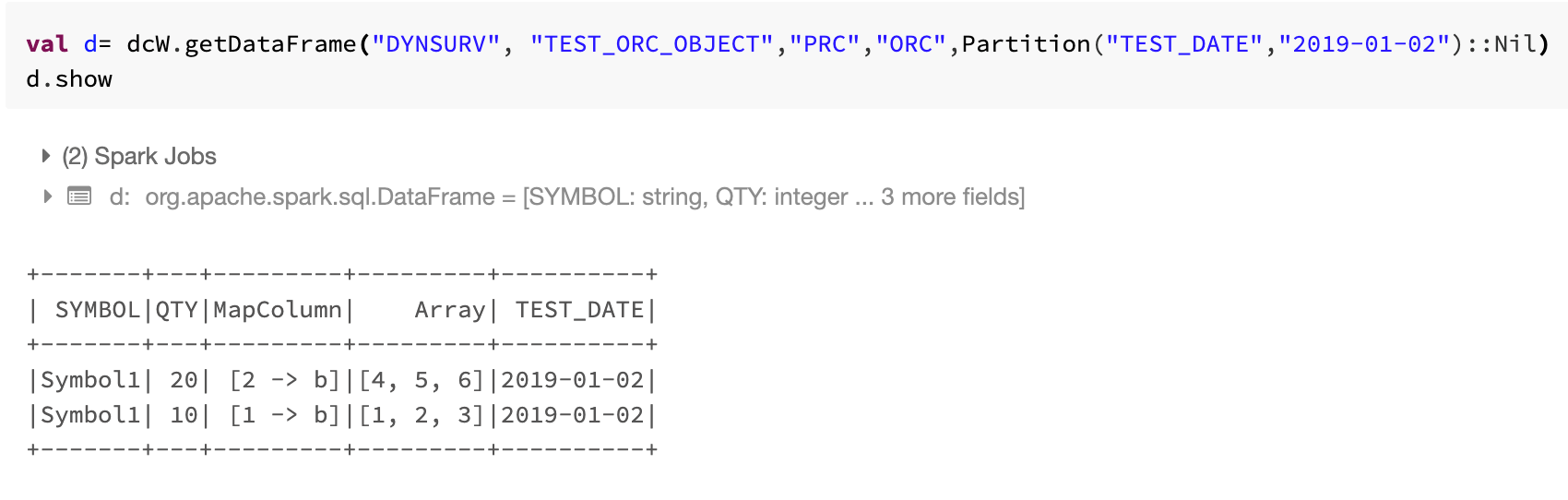
Complex datatype is supported by PARQUET and ORC format only.
8. Explore the following examples of all other feature sets:
dmWipeNamespace
Syntax-
dmWipeNamespace(nameSpace: String)
Eg-
val dataCatalog = new DataCatalog(spark, host, credName, AGS, SDLC, credComponent)
dataCatalog.dmWipeNamespace("testNamespace")
getDataAvailability
Syntax-
getDataAvailability(namespace: String,
objectName: String,
usage: String,
fileFormat: String,
schemaVersion: Integer = null): DataFrame
| Input Parameters | DataType | Default Value | Required | Description |
|---|---|---|---|---|
| namespace | String | Y | The namespace for the business object data. | |
| objectName | String | Y | The name of the business object definition. | |
| usage | String | PRC | The business object format usage. | |
| fileFormat | String | PARQUET | The business object format file type. | |
| schemaVersion | Integer | latest schema version registered in herd | The schema version for the business object data. |
Eg-
val dataCatalog = new DataCatalog(spark, host, credName, AGS, SDLC, credComponent)
val df = dataCatalog.getDataAvailability("testNamespace", "testObject", "PRC", "TXT")
getDataAvailability
Syntax-
getDataAvailabilityRange(namespace: String,
objectName: String,
usage: String,
fileFormat: String,
partitionKey: String,
firstPartValue: String,
lastPartValue: String,
schemaVersion: Integer = null): DataFrame
| Input Parameters | DataType | Default Value | Required | Description |
|---|---|---|---|---|
| namespace | String | Y | The namespace for the business object data. | |
| objectName | String | Y | The name of the business object definition. | |
| usage | String | PRC | The business object format usage. | |
| fileFormat | String | PARQUET | The business object format file type. | |
| firstPartValue | String | Y | First partition value of business object data for getting data availability. | |
| lastPartValue | String | Y | Last Partition value of business object data for getting data availability. | |
| schemaVersion | Integer | latest schema version registered in herd | The schema version for the business object data. |
Eg-
val dataCatalog = new DataCatalog(spark, host, credName, AGS, SDLC, credComponent)
val df = dataCatalog.getDataAvailabilityRange("testNamespace", "testObject", "PRC", "TXT", "TRADE_DT", "2019-01-01", "2020-01-01")
getPartitions
Syntax-
getPartitions(namespace: String,
objectName: String,
usage: String,
fileFormat: String,
schemaVersion: Integer = null): StructType
| Input Parameters | DataType | Default Value | Required | Description |
|---|---|---|---|---|
| usage | String | PRC | The business object format usage. | |
| objectName | String | Y | The name of the business object definition. | |
| namespace | String | Y | The namespace for the business object data. | |
| fileFormat | String | PARQUET | The business object format file type. | |
| schemaVersion | Integer | latest schema version registered in herd | The schema version for the business object data. |
Eg-
val dataCatalog = new DataCatalog(spark, host, credName, AGS, SDLC, credComponent)
val df = dataCatalog.getPartitions("testNamespace", "testObject", "PRC", "TXT")
getSchema
Syntax-
getSchema(namespace: String,
objectName: String,
usage: String,
fileFormat: String,
schemaVersion: Integer = null): StructType
| Input Parameters | DataType | Default Value | Required | Description |
|---|---|---|---|---|
| usage | String | PRC | The business object format usage. | |
| schemaVersion | Integer | latest schema version registered in herd | The schema version for the business object data. | |
| objectName | String | Y | The name of the business object definition. | |
| namespace | String | Y | The namespace for the business object data. | |
| fileFormat | String | PARQUET | The business object format file type. |
Eg-
val dataCatalog = new DataCatalog(spark, host, credName, AGS, SDLC, credComponent)
val schema = dataCatalog.getSchema("testNamespace", "testObject", "PRC", "TXT")
Conclusion
Using DataCatalog API in conjunction with herd to store and retrieve data in Spark DataFrames is beneficial to the user because it provides ease of access to huge datasets in big data format. DataCatalog API improves the readability of the data as it allows schema, null values, escape characters and delimiters to be specified by the user while saving the data; it also allows complex datatype support, which can make things easier for more complex data sets.
For additional information on DataCatalog API, visit FINRA’s GitHub page.